Want Real-Time Local Info? Scrape Google Maps Using Python the Easy Way
12 min read

12 min read
Table of Contents
Table of Contents
Think about how frequently you open Google Maps—not just for directions, but to find out restaurants, check store timings, or read evaluations before visiting a new business. Now, consider tapping into that equal pool of records on a massive scale. That’s what Google Maps scraping is all approximately.
It’s the procedure of programmatically extracting publicly available information from Google Maps—details like business names, contact data, places, categories, reviews, and rankings. While this data is seen to everyone, manually copying it for thousands of businesses is impractical. Scraping solves this hassle through automating the gathering method, allowing companies, entrepreneurs, researchers, and builders to gather huge amounts of structured, location-based information efficiently and at scale.
This practice is often used to conduct business directories, perform market analysis, monitor competitors or build site-conscious apps. But to do it right, it is important to understand what it is, why it is useful, and how it is often used.
Google Maps scraping is a method of automating the collection of structured data from Google Maps results. It involves using robots, scripts or APIs to extract public details about companies, locations, services and user-generated content such as reviews. The data collected usually includes:
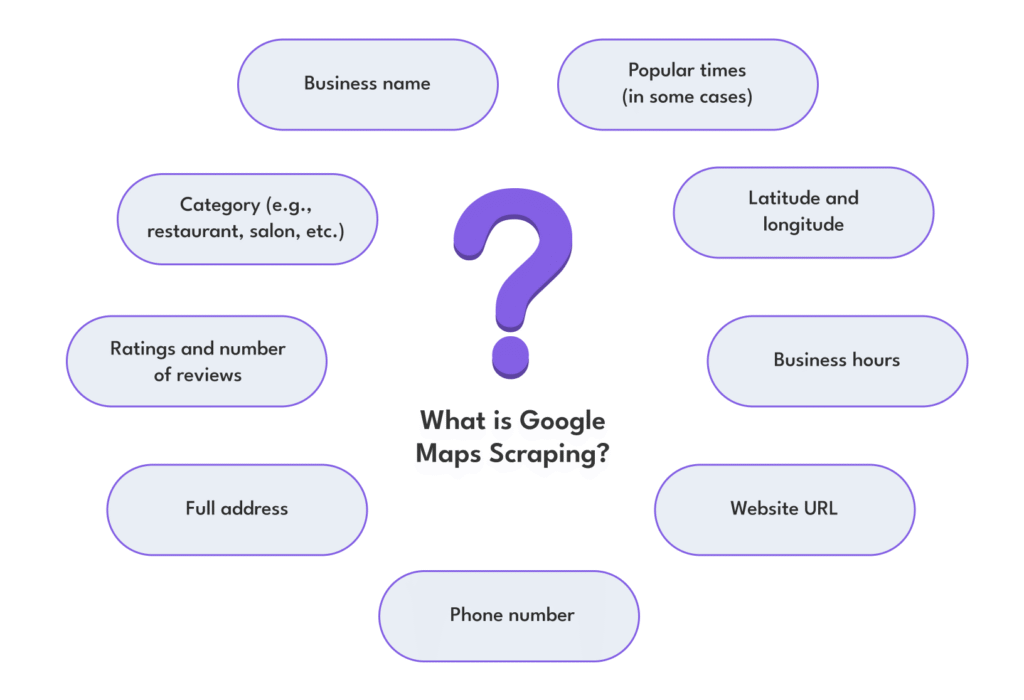
This data is often structured and saved into formats like CSV or JSON for further analysis or integration with business intelligence tools.
Importantly, it’s not hacking or breaching privacy. The data scraped is already visible to everyone—it’s just collected more efficiently for smart use in apps, research, or business planning.
The reasons for scraping Google Maps data vary across industries, but the most common motivator is the value of real-time, hyper-local business intelligence. This information provides unmatched visibility for companies and data analysts in the local marketplace.
For example, marketers use scraped data to analyze competitors in a specific area, understanding their reviews, how often they are visited, and what customers say about them. Real estate professionals use it to study facilities in the neighbourhood and evaluate property trends. Entrepreneurs launching a new venture often scrape data to assess saturation levels in a given location or identify underrepresented categories in a city.
Another important advantage is lead generation. Sales teams retrieve contact details for local businesses to build very targeted outreach campaigns. By accessing updated business listings, outdated databases are avoided and ensuring better response rates.
Ultimately, scraping Google Maps offers a fast, scalable way to understand what’s happening at a local level, empowering smarter decisions backed by data, not guesswork.
Google Maps data is not just about maps – it’s about people, places and behaviour. Here are some of the most common and effective use cases where scraped data becomes a game-changer:
These applications demonstrate just how versatile and powerful Google Maps scraping can be when done responsibly and with clear intent.

Scraping Google Maps data may sound straightforward from a technical point of view, but legally, it is a grey zone that needs to be carefully considered. While the data you access is public, Google still restricts how you can use it, especially on a scale. Abusing or aggressively scratching the platform without understanding the legal boundaries can lead to serious consequences, ranging from IP bans to potential legal actions.
So, before diving into large-scale data extraction, it’s essential to consider what Google allows, how to scrape responsibly, and the steps you can take to reduce legal risks.
Every user of Google Maps, whether a casual visitor or a developer, agrees to Google’s Terms of Service. And these terms clearly outline restrictions on scraping.
According to Google’s guidelines, automated access to their services is generally prohibited without permission. This includes crawling, scraping or harvesting data from Google Maps unless you use an official API as the Google Place API. These APIs have use limits and strict licensing agreements, designed to protect Google’s commercial interests and control how the data is distributed.
Violating these terms can result in:
This is why many companies choose to use third-party data providers or scraping services that operate within legal boundaries, especially when dealing with large-scale or commercial use cases.
Even if you are not violating legal rules, there is still a line between responsible scraping and harmful activity. Ethical scraping is not just avoiding lawsuits – it is about respecting platforms, users and data quality.
To scrape ethically:
Being transparent about how you use the data and offering value through your application or insights can go a long way in ensuring you’re seen as a responsible actor in the ecosystem.
One of the most common challenges that scrapers experience is being prohibited by Google. Scraping too aggressively or frequently using the same IP address can get you identified by Google’s systems, which are meant to detect non-human conduct.
To avoid bans and reduce legal risks:
Also, always keep the legal backup: consult a legal expert, especially if you manage a company that strongly depends on scraped data. This step helps ensure compliance with broader data protection laws and laws such as GDPR or CCPA, depending on the regions you are working on.
When your Python environment is set up and the necessary libraries are in place, you are ready to start scratching Google Maps. Although this may sound complex to begin with, the process becomes much easier when you break it into smaller tasks – for example, pulling out business entries, drawing contact information and collecting rankings or reviews.
Scraping Google Maps data generally involves loading the map, simulating user actions such as searching or scrolling, and extracting relevant information from each business listing. Since Google Maps content is often dynamically loaded via JavaScript, this step is typically handled using Selenium, providing full browser automation.
Let’s explore the key elements you’d typically extract when scraping Google Maps.
The heart of any Google Maps scraping task begins by collecting business listings based on a search. This can be anything from restaurants in São Paulo to salons in Seoul.
Here’s what usually happens under the hood:
This first step lays the foundation for the rest of the scraping process. Once you have the listings, you can then drill deeper into each one to extract more detailed information.
After collecting the business names and URLs, the next step is to fetch contact information. This often requires opening each business profile page individually and scraping the visible details from there.
Here’s what scrapers typically collect:
Since this data is part of the public listing, it’s visible to any Google Maps user—but automating its extraction helps when dealing with hundreds or thousands of businesses.
One important note: Email addresses are rarely listed directly in Google Maps, so if they’re needed, you might have to follow the business’s website link and extract the email from there. This adds an extra layer to your scraping flow.
Customer feedback plays a massive role in decision-making. That’s why many scraping projects aim to capture user ratings and written reviews as part of the dataset.
Ratings and reviews give you:
This part of the process is slightly more complex, especially if you want multiple reviews per business. You’ll likely need to scroll inside the reviews section of each listing (which is loaded dynamically) and allow all content to render before scraping it. Selenium handles this well, but it may slow down the process if you’re collecting hundreds of reviews per listing.
Scraping data is only half the job. What you do with the information afterwards is what determines the value. Once you have collected business names, contact information, and reviews from Google Maps, the next step is to organize the data properly. Storing it in a format that is easy to access, analyze, and share will make it far more useful. This is where it becomes important to save to CSV or Excel files.
Both formats serve the same basic purpose—storing structured data in rows and columns—but they offer slightly different benefits depending on how you plan to use the output.
The most common formats for storing scraped data are:
Using Python, you can easily save scraped data to either format with the help of libraries like pandas or openpyxl.
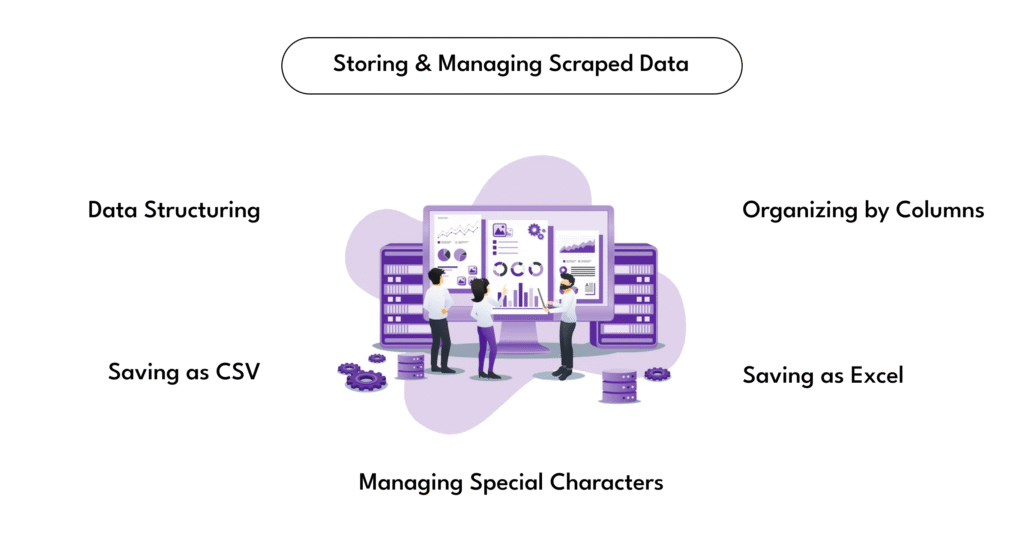
Here’s how this typically works:
The elimination of Google Maps data may seem like a technical difficulty at first, but when broken – from configuring your Python environment to extracting business details and saving results in CSV or Excel, it becomes a structured and repeatable process. Whether you collect information from local companies, conduct competitive surveys, or create a personalized database, scraping Google Maps can be a game-changer. It offers access to relevant, location-based data that would otherwise take hours to gather manually.
As you go, consider improving your scraping workflows with capabilities such as automatic retries, user-agent rotation, and even proxy support to handle more complex cases. The key is to start modest, stay within ethical boundaries, and gradually expand your setup as your needs grow. With the right methodology and ethical practices, you’ll not only save time. You’ll also discover new ways to acquire insights and make informed choices using real-time location data.












