What Is Data Scraping? A Complete Guide for Modern Businesses
9 min read

9 min read

Table of Contents
Table of Contents
Data scraping is an automated process to obtain information from websites or online platforms. With data scraping, users can collect huge amounts of data—such as prices, user reviews, financial trends, or business listings—without manually copying and pasting it. This procedure turns web content into a clean, structured dataset that may be stored in CSV, JSON, or Excel format for further analysis or integration into the software.
Essentially, it is like hiring a virtual assistant who analyses web pages quickly and retrieves the information you need. Although this may sound like magic, it is actually a controlled and systematic approach driven by scraping tools and technology that recreates human browsing.

At the technical level, data scraping starts when a scrapebot sends a request to a web page. Just like when you visit a website through your browser, the Server replies with HTML code. This code contains all text, images and information that is displayed on the page. A scraper doesn’t have to see the visual; It just needs the code behind it.
The scraper tool reads this HTML code, finds patterns such as title tags, price labels, or data tables, and extracts the relevant parts. Then, the tool cleans the data — removing any unwanted tags or elements — and formats it into structured fields. These fields are saved in files or databases, ready for analysis or automation.
Some scrapers are designed for single-use tasks, while others are automated to run on schedules and gather real-time updates continuously. More advanced scraping involves headless browsers that can handle JavaScript, allowing access to content that loads dynamically.
In today’s digital economy, data is power, and data scraping is the simplest way to take advantage of this power. Every industry increasingly depends on real-time, accurate, and large-scale data to make solid judgments. Manual data collection is very slow and inefficient, and it does not meet the needs of modern businesses.
Scraping helps companies gain competitive insights, monitor market trends, track pricing fluctuations, and observe customer sentiment. It enables automated workflows, faster reporting, and instant reaction to market changes. From small businesses tracking their local competition to global enterprises monitoring international pricing, data scraping has become a daily need.
It also powers innovation. Startups often build tools and dashboards fueled by scraped data. Journalists and researchers use scraping to uncover hidden patterns. Governments and NGOs rely on it for public monitoring, while SEO agencies use it for rank tracking and link analysis. Without scraping, most of this work would be impossible or extremely slow.
Data scraping is legal, greatly depending on how, what, and where you scrape. Scraping publicly available data on websites without login restrictions is generally lawful. Scraping becomes a grey subject when it comes to copyrighted content, personal information, or protected databases.
Websites frequently include scraping policies in their terms of service or robots.txt files. Ignoring these guidelines may result in legal warnings or being blocked. In addition, data privacy rules such as GDPR (in Europe) and CCPA (in California) prohibit the elimination of content generated by the user or personal identifiers without consent.
Scrapers should always follow website rules, avoid gathering private or sensitive data, and scrape only for legitimate purposes such as research, price tracking, or market analysis. Responsible scraping also entails employing appropriate delay intervals and not overloading servers with requests.
Data scraping isn’t limited to one field — it has become a foundational technology across multiple sectors:
Each use case leverages scraping differently, but the core goal is the same — to gain instant access to valuable, structured information.
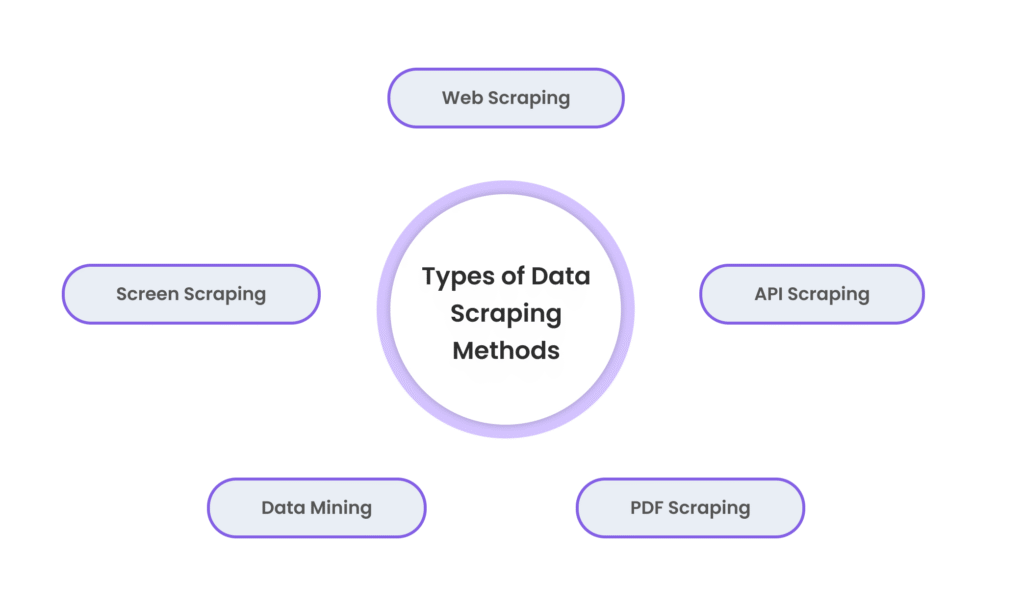
Data scraping encompasses various methods that cater to different use cases. Here’s an overview of the most common types:
➤ Web Scraping: This is the most traditional and widely used form of data scraping. It comprises gathering information from several websites and webpages. Web scraping allows you to capture structured and unstructured data, including text, images, and links.
➤ API Scraping: The API scraping, compared to the elimination of the web, extracts data from an application programming interface (API) instead of a site. Many online businesses, such as social media platforms or news sites, offer APIs that allow users to access their data in a structured format, such as JSON or XML, which can be easily processed later.
➤ Screen Scraping: This involves extracting output information or apps from the computer screen. Screening of the screen is often used to collect data from old systems or interfaces that do not have a standard API for interaction.
➤ Data Mining: Data mining includes a broader selection of data extraction and analysis. It involves the extraction of standards and insights from massive data sets, which can be collected by scraping or other means, such as databases. Data mining is often used to find hidden trends and patterns that can help in decisions.
➤ PDF Scraping: Some companies use PDF documents as part of the workflow. PDF scraping is the process of obtaining structured data from PDF reports, invoices and other document formats, facilitating work with data stored in these formats.
There are many scraping tools available, ranging from no-code platforms to advanced developer libraries:
Choosing the right tool depends on your goals, website complexity, and technical comfort level.
Despite its advantages, scraping isn’t always smooth sailing. One major issue is frequent website structure changes. If a website updates its layout or class names, your scraper may stop working until it’s adjusted. Another problem is blocking mechanisms — many sites use anti-bot systems like IP blocking, CAPTCHA challenges, and rate limits.
Data inconsistency is another challenge. Sometimes, the scraped data may be incomplete, messy, or duplicated. Cleaning and validating data requires extra time and tools. Scalability also matters — scraping a few pages is easy, but collecting data from thousands of URLs regularly requires solid architecture, error handling, and reliable proxies.
These three often get mixed up, but they serve different purposes:
When no API exists or doesn’t meet the need, scraping becomes the go-to method.
Most websites actively try to detect and block scraping activity. To prevent this, ethical scrapers use smart practices:
These methods help scrapers stay undetected and reduce the risk of being blocked or banned.
Data scraping is more than just a technical term; It is a practical answer for anyone who needs fast, accurate and large-scale data access. Scraping provides valuable insight, whether you are running a start-up, conducting academic research, optimising for search engines or looking at competitors.
Data scraping, when done ethically, legally and intelligently, can provide a significant advantage in obtaining and using public data online. Understanding the process, tools and problems allows you to use it as a long-term growth plan instead of just a skill.












