No-Code Solutions to Scrape Google Scholar Effortlessly
7 min read

7 min read

Table of Contents
Table of Contents
In today’s world of research, staying ahead means collecting dependable and relevant data quickly. One of the best platforms for educational research is Google Scholar, which provides a large repository of scholarly articles, theses, books, and more. However, manually searching and collecting this data may be time-consuming, particularly for those working on huge projects. Luckily, the ability to scrape Google Scholar can solve this problem, streamlining the data collection process and saving valuable time for researchers.
But what in case you don’t know how to code? Don’t worry! In this guide, you’ll discover ways to scrape Google Scholar with no coding knowledge. We’ll take you via easy tools, strategies, and best practices to help you extract data effortlessly.
For instance, if you want to collect citation details, abstracts, or author names from Google Scholar, scraping can manage this effectively. Though it’s a powerful method, no one can code it anymore. That’s why we’ll focus on tools that let you scrape without writing a single line of code.

Google Scholar is a treasure trove of educational data. Whether you’re a student, researcher, or data analyst, scraping data from this platform can provide a competitive aspect. Here’s why scraping Google Scholar is useful:
Scraping Google Scholar gives you access to information that would otherwise require hours to gather manually.
Before you begin scraping, it’s essential to understand the legal components. While scraping isn’t inherently illegal, some websites have policies in opposition to automated data extraction.
Google Scholar’s terms of service restrict large-scale automatic queries which can slow down their servers. To stay compliant:
You reduce the risk of violating their terms by scraping in moderation and adhering to their guidelines.
You don’t need to be a programmer to scrape Google Scholar. Several no-code tools make web scraping easy and accessible for everyone. Here are the top tools to help you get started:
Web Scraper is a popular Chrome extension that simplifies scraping for beginners. It’s user-friendly, and you could use it to set up basic scraping tasks with any coding.
How to use Web Scraper:
This tool is perfect for small-scale scraping, and it’s free to use!
Octoparse is an advanced no-code web scraping tool that offers both free and premium versions. It allows you to scrape data from websites with the aid of creating workflows, and it offers cloud-based data extraction.
How to use Octoparse:
Octoparse is perfect for scraping larger data sets and provides a cloud-based solution for continuous scraping.
ParseHub is a leading no-code solution that provides a user-friendly visual interface for extracting data from websites. You can use it to scrape Google Scholar by creating a project and teaching the tool what data to extract.
How to use ParseHub:
ParseHub is perfect for scraping both static and dynamic content.
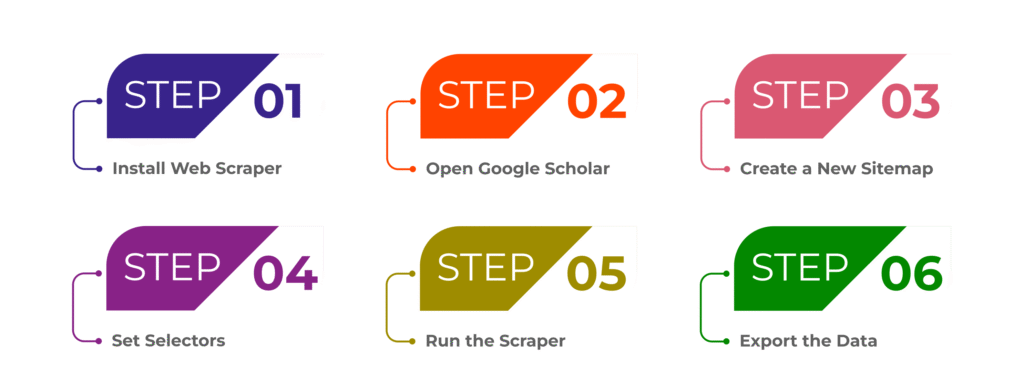
Let’s walk through a simple process to scrape Google Scholar using the Web Scraper Chrome extension:
1. Install Web Scraper: navigate to the Chrome Web Store, enter “Web Scraper” in the search bar, and proceed to add the extension to your browser.
2. Open Google Scholar: Navigate to Google Scholar and search for the keyword or topic you’re interested in.
3. Create a New Sitemap: Click on the Web Scraper icon and create a new sitemap for your task. This will allow you to define the structure of the data you want to scrape.
4. Set Selectors: Using the ‘Selector’ tool, define the elements you want to scrape, such as article titles, links, authors, or publication dates. You can click on these elements, and Web Scraper will automatically identify them.
5. Run the Scraper: Once everything is set, run the scraper. Web Scraper will visit each result on Google Scholar and extract the data based on your selectors.
6. Export the Data: After scraping is complete, export the data into a CSV file, which you can easily open in Excel for further analysis.
To get the most out of your scraping efforts, follow these best practices:
If scraping Google Scholar isn’t an option for you due to time constraints or restrictions, here are some alternatives:
1. Semantic Scholar: A free research tool that allows users to search academic papers. They also offer an API for data extraction.
2. CORE: An open-access research repository with an API for extracting research articles.
3. Publish or Perish: A citation analysis tool that can search Google Scholar and provide similar data without needing to scrape.
These alternatives offer different ways to gather academic data without resorting to scraping.
Scraping Google Scholar without coding is possible with the right tools. Whether you’re collecting research papers, monitoring citations, or reading creator trends, web scraping can significantly speed up your data collection process. Tools like Web Scraper, Octoparse, and ParseHub provide easy-to-use interfaces that make web scraping accessible even for beginners.
Just remember to scrape responsibly, stay within legal boundaries, and ensure the data you collect is accurate and well-organized. With this beginner’s guide, you’re now ready to dive into Google Scholar scraping with no coding skills!
Yes, there are several no-code tools available that let you scrape Google Scholar easily. These tools are user-friendly and don’t require any programming skills.
Scraping Google Scholar can violate its terms of service. To avoid legal issues, it’s important to check Google’s policy and use the data ethically, ensuring you’re not scraping private or sensitive information.
Some tools, like Octoparse, offer free versions with limited features, while others may require a paid subscription for advanced functionalities like data export or scheduling.
For beginners, the Web Scraper Chrome Extension is the easiest tool. It’s simple to use and allows you to extract data directly from your browser without installing additional software.












