Scrape Images from a Website Without Coding: Simple Methods Explained
7 min read

7 min read

Table of Contents
Table of Contents
Have you ever wanted to scrape images from a website but found yourself stuck downloading them one by one? It’s a tedious process, isn’t it? That’s in which automated image extraction, additionally known as web scraping for images, comes in. Imagine extracting hundreds or maybe thousands of images from a website with only a few clicks—without breaking a sweat!
But before you dive in, there’s a lot to understand. How do websites store images? How can you extract them effectively? And most importantly, how are you going to do it without getting blocked? In this beginner guide, we’ll cover everything you need to know about scraping images from a website, from how images are structured on web pages to the safest and most efficient methods to extract them.
Before scraping images, you need to understand where and how they are stored. Websites don’t just scatter images randomly—they follow structured methods to display them. Here are the main ways images are embedded in web pages:
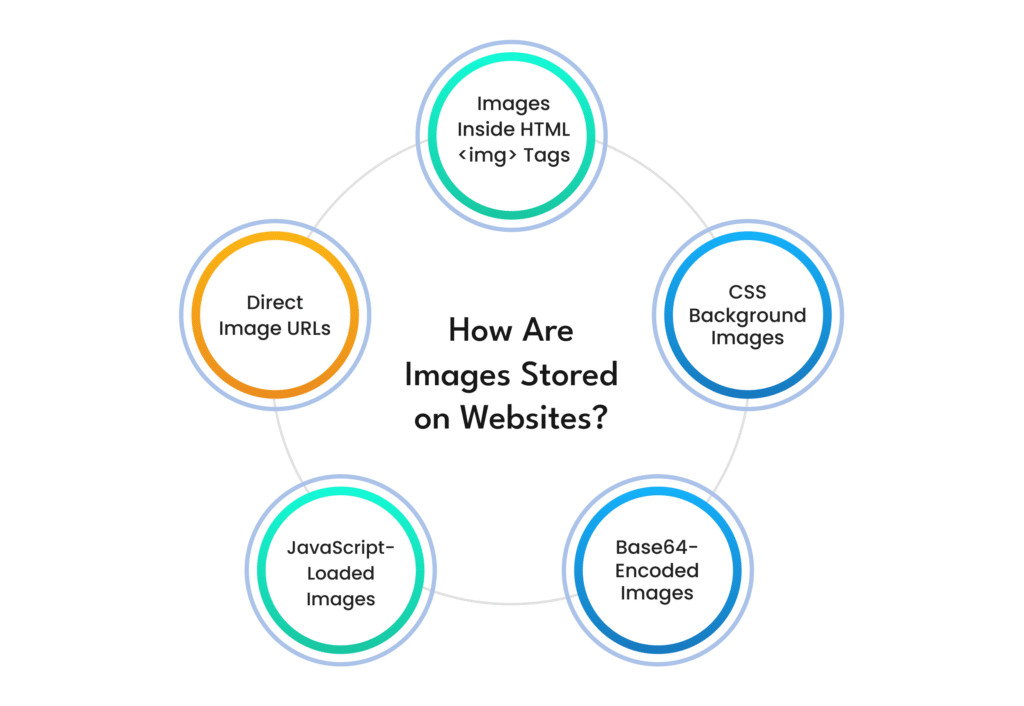
1. Direct Image URLs
Images on certain websites are stored as direct URLs. Scraping these is a bit tricky because stylesheets embed them rather than the primary HTML code. For example:
👉 https://example.com/images/product1.jpg
You can simply collect these URLs and download the images. However, not all websites make it that easy.
2. Images Inside HTML <img> Tags
Most internet pages use <img> tags to display images. These tags incorporate attributes like src (source), alt (alternative textual content), and class.
3. CSS Background Images
A few websites use CSS styles to apply background images instead of <img> tags. These are a bit tricky to scrape because they’re embedded in stylesheets rather than the primary HTML code.
4. JavaScript-Loaded Images
Certain websites load images dynamically using JavaScript. This means that when you first load the page, the image URLs may not be visible in the raw HTML. Instead, they are inserted later using JavaScript scripts. You may need to render JavaScript before extracting these images.
5. Base64-Encoded Images
Certain websites use Base64 encoding, which appears as a long string rather than a traditional image URL, to embed images directly in HTML.While you can decode and save these images, it’s a less common format for bulk extraction.
Now that you recognise how images are stored, let’s communicate about how to extract them without triggering safety features like CAPTCHA or IP bans. Websites put into effect diverse anti-scraping strategies to save their computerized bots from overloading their servers. Here’s how you could scrape images safely and effectively:
Before scraping a website, examine its robots.txt file. This file contains policies about what can and cannot be scraped. If a website prohibits image scraping, respecting its policies is preferable to prevent legal troubles.
Websites can detect scraping by using searching at the HTTP headers. To avoid suspicion, ensure your scraper sends headers just like those of a real browser, including:
Websites may block you if you send too many requests from the same IP address. To avoid this:
If images are loaded via JavaScript, an easy scraper won’t work. Instead, you want a headless browser (like Puppeteer or Selenium) that could load and interact with JavaScript content similar to a real user.
Scraping too fast can raise red flags. Instead of bombarding a website with requests, use randomized delays between requests to make your activity appear more natural.
Once you’ve scraped the images, decide how to store them. You can:
For large-scale scraping, ensure your storage solution can handle bulk downloads without running out of space.
Web scraping requires not only technological expertise but also an understanding of the legal and ethical implications. Not all images are free to use, and scraping copyrighted content without permission might result in legal action. Here’s something to keep in mind:

➤ Check Copyright and Licensing: If images have copyright protection, you cannot commercially use them without permission.
➤ Follow Fair Use Policies: Some jurisdictions allow the use of certain content under fair use.
➤ Ask for Permission: If you need images for commercial purposes, reach out to the website owner for approval.
➤ Respect Website Terms of Service: Some sites explicitly prohibit scraping in their terms. Always read them before scraping.
By following ethical guidelines, you can avoid legal risks and build a responsible scraping strategy.
Now that you’ve learnt the fundamentals of image scraping, let’s look at some advanced strategies that will help you extract images more quickly, even from complicated websites with anti-scraping mechanisms in place.
Many modern websites use infinite scrolling to load more images dynamically as users scroll down. Traditional scrapers may fail to capture all images because they only fetch the initial page source. To handle this:
If several pages contain the images you require, you must navigate through them. To achieve this:
Some websites use watermarks to prevent unauthorized image use. While you cannot legally remove them, you can:
Websites often display lower-quality thumbnails instead of full-resolution images. You can:
Scrape images from a website efficiently for research, content preservation, or AI training datasets. However, it’s essential to approach it carefully. Understanding how websites store images, using safe scraping techniques, and following ethical guidelines will help you collect images quickly while staying within the law.
So, the next time you need to collect hundreds of images, remember that you don’t have to do so manually! With the right approach, you can automate the process and make image extraction easy.












